Summary: “Object and Action Recognition Assisted by Computational Linguistics”.
The aim of this project is to investigate how computer vision methods such as object and
action recognition may be assisted by computational linguistic models, such as WordNet.
The main challenge of object and action recognition is the scalability of methods from
dealing with a dozen of categories (e.g. PASCAL VOC) to thousands of concepts (e.g.
ImageNet ILSVRC). This project is expected to contribute to the application of automated
visual content annotation and more widely to bridging the semantic gap between
computational approaches of vision and language.
Poster for the WCE’13 paper that was awarded “Best Student Paper” award,
INTRODUCTION:
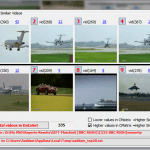
Videos, especially the compressed ones, became a major part of our daily life. With the amount of videos growing exponentially, Scientists are being pushed to develop robust tools that could efficiently index and retrieve videos in a way similar to human perception of similarity.
*Based on http://www.youtube.com/yt/press/statistics.html
PROBLEM
§Manual annotation is a hard work and annotations are not always available for utilization.
§We need more smarter tagging process for videos.
§With the increasing of compressed videos, more efficient techniques are required to work directly on compressed files, without need for decompression.
AIM
Our aim is to build a framework that will operate on compressed videos (utilizing the DC-images sequence),
CONCLUSION
•DC-IMAGE is suitable for cheaper computations and could be used as basic building block for real-time processing.
•Local features proved to be effective on DC-image, after our introduced modification.
(Click Semantic Video Annotation-with Knowledge ” https://amrahmed.blogs.lincoln.ac.uk/files/2013/03/Semantic-Video-Annotation-with-Knowledge.pdf , to download the pdf)
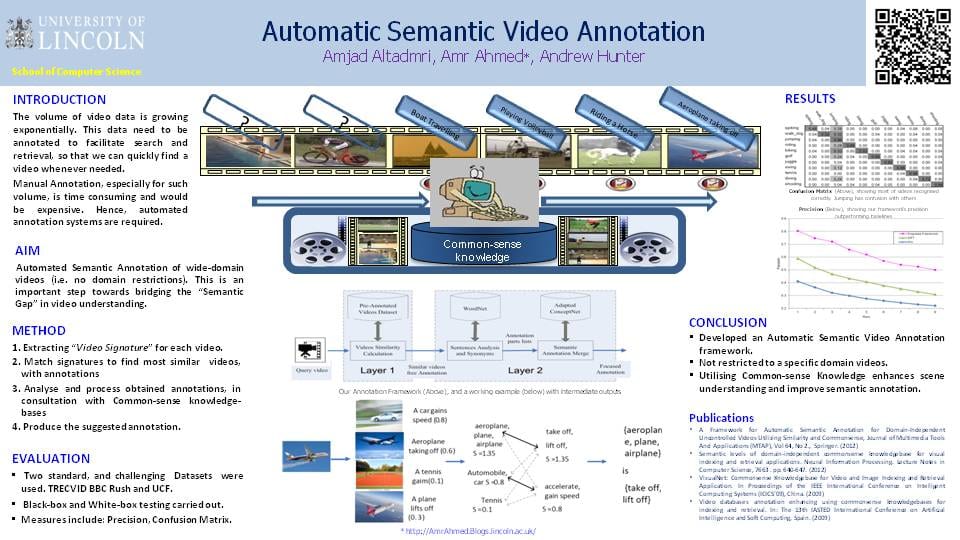
INTRODUCTION
The volume of video data is growing exponentially. This data need to be annotated to facilitate search and retrieval, so that we can quickly find a video whenever needed.
Manual Annotation, especially for such volume, is time consuming and would be expensive. Hence, automated annotation systems are required.
AIM
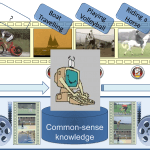
Automated Semantic Annotation of wide-domain videos (i.e. no domain restrictions). This is an important step towards bridging the “Semantic Gap” in video understanding.
METHOD
1. Extracting “Video Signature” for each video.
2. Match signatures to find most similar videos, with annotations
3. Analyse and process obtained annotations, in consultation with Common-sense knowledge-bases
4. Produce the suggested annotation.
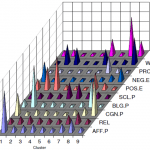
EVALUATION
• Two standard, and challenging Datasets were used. TRECVID BBC Rush and UCF.
• Black-box and White-box testing carried out.
•Measures include: Precision, Confusion Matrix.
CONCLUSION
•Developed an Automatic Semantic Video Annotation framework.
•Not restricted to a specific domain videos.
•Utilising Common-sense Knowledge enhances scene understanding and improve semantic annotation.