Three members of the Lincoln School of Computer Science, and the DCAPI group, have attended the Vision & Language (V&L) Network workshop, 13-14th Dec. 2012 in Sheffield, UK.
Amr Ahmed, Amjad Al-tadmri and Deema AbdalHafeth attended the event, where Amjad and Deema delivered 2 oral presentations and 2 posters about their research work:
1. VisualNet: Semantic Commonsense Knowledgebase for Visual Applications
2.Investigating text analysis of user-generated contents for health related applications
Amjad Altadmri and Amr Ahmed around their poster at the Vision & Language Net workshop, 13-14th Dec 2012, Sheffield, UK.Deema AbdalHafeth and Amr Ahmed at the Vision & Language Net workshop, 13-14th Dec 2012, Sheffield, UK.
The event included tutorial sessions (Vision for language people, and language for vision people). We had an increased presence this year.
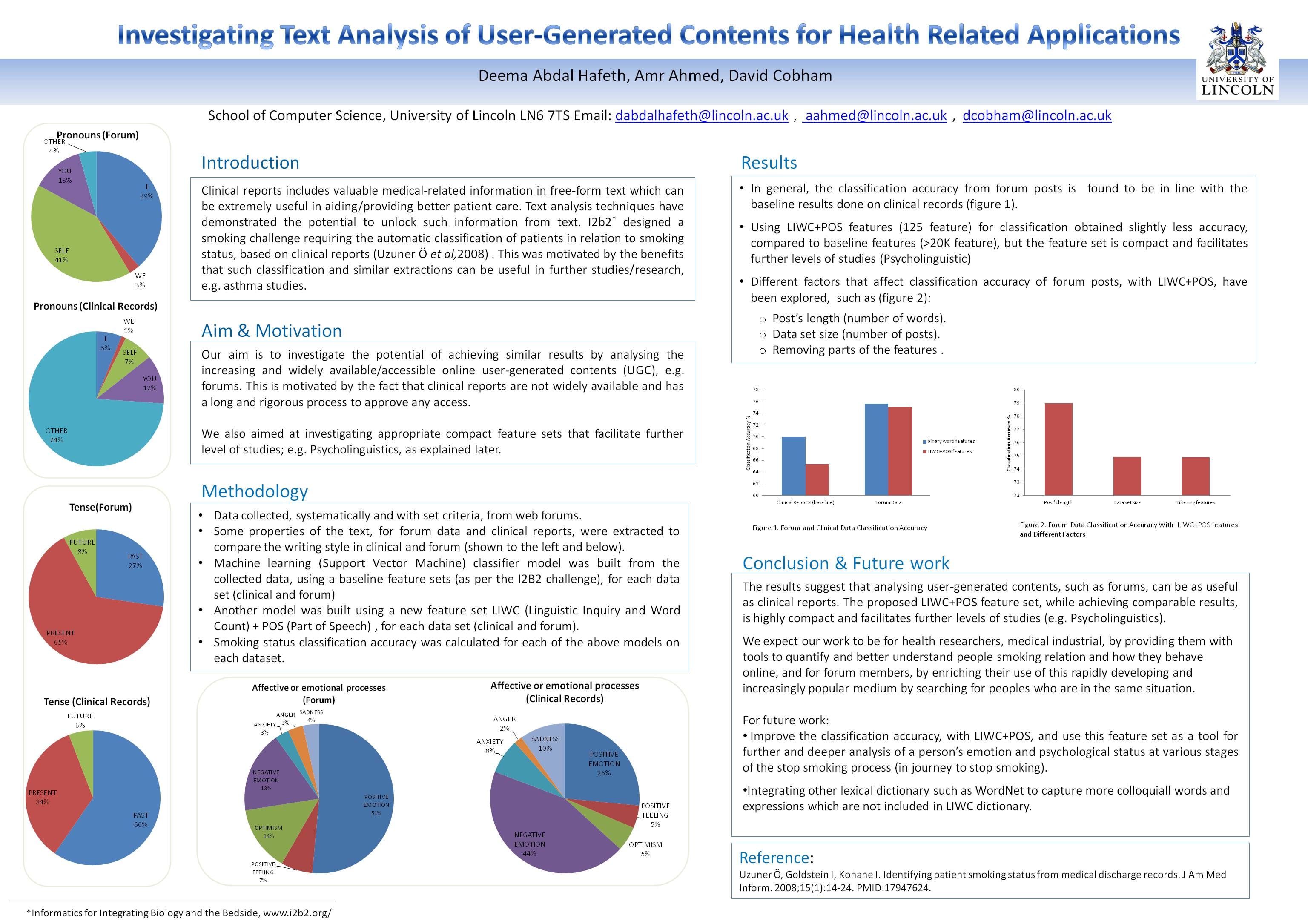
Clinical reports includes valuable medical-related information in free-form text which can be extremely useful in aiding/providing better patient care. Text analysis techniques have demonstrated the potential to unlock such information from text. I2b2* designed a smoking challenge requiring the automatic classification of patients in relation to smoking status, based on clinical reports (Uzuner Ö et al,2008) . This was motivated by the benefits that such classification and similar extractions can be useful in further studies/research, e.g. asthma studies.
Aim & Motivation
Our aim is to investigate the potential of achieving similar results by analysing the increasing and widely available/accessible online user-generated contents (UGC), e.g. forums. This is motivated by the fact that clinical reports are not widely available and has a long and rigorous process to approve any access.
We also aimed at investigating appropriate compact feature sets that facilitate further level of studies; e.g. Psycholinguistics, as explained later.
Methodology
•Data collected, systematically and with set criteria, from web forums.
•Some properties of the text, for forum data and clinical reports, were extracted to compare the writing style in clinical and forum (shown to the left and below).
•Machine learning (Support Vector Machine) classifier model was built from the collected data, using a baseline feature sets (as per the I2B2 challenge), for each data set (clinical and forum)
•Another model was built using a new feature set LIWC (Linguistic Inquiry and Word Count) + POS (Part of Speech) , for each data set (clinical and forum).
•Smoking status classification accuracy was calculated for each of the above models on each dataset.
Results
•In general, the classification accuracy from forum posts is found to be in line with the baseline results done on clinical records (figure 1).
•
•Using LIWC+POS features (125 feature) for classification obtained slightly less accuracy, compared to baseline features (>20K feature), but the feature set is compact and facilitates further levels of studies (Psycholinguistic)
•
•Different factors that affect classification accuracy of forum posts, with LIWC+POS, have been explored, such as (figure 2):
o Post’s length (number of words).
o Data set size (number of posts).
o Removing parts of the features .
Conclusion & Future work
The results suggest that analysing user-generated contents, such as forums, can be as useful as clinical reports. The proposed LIWC+POS feature set, while achieving comparable results, is highly compact and facilitates further levels of studies (e.g. Psycholinguistics).
We expect our work to be for health researchers, medical industrial, by providing them with tools to quantify and better understand people smoking relation and how they behave online, and for forum members, by enriching their use of this rapidly developing and increasingly popular medium by searching for peoples who are in the same situation.
For future work:
• Improve the classification accuracy, with LIWC+POS, and use this feature set as a tool for further and deeper analysis of a person’s emotion and psychological status at various stages of the stop smoking process (in journey to stop smoking).
•Integrating other lexical dictionary such as WordNet to capture more colloquiall words and expressions which are not included in LIWC dictionary.
Reference:
Uzuner Ö, Goldstein I, Kohane I. Identifying patient smoking status from medical discharge records. J Am Med Inform. 2008;15(1):14-24. PMID:17947624.
We just had 2 posters and oral presentations accepted for the coming Vision & Language (V&L) Network workshop, 13-14th Dec. 2012 in Sheffield, UK. This is a good representation from Lincoln (and from the DCAPI group).
1. VisualNet: Semantic Commonsense Knowledgebase for Visual Applications
2.Investigating text analysis of user-generated contents for health related applications
This is the Eid Day (Celebrating the end of the Holy Month of Ramadan). Memebers of the Egyptian Paralympic Teams have joined the Lincoln community in the Eid Prayer, before heading to their training venues.
Eid Prayer: Members of the Egyptian Paralympics Team joined the Lincoln’s community for Eid prayer and celebration, on their first day of the pre-games training camp.
Then, the teams split:
* Sitting Volly Ball and Table Tennis teams gone to their training venue, the Sports Centre at the University of Lincoln.
* Powerlifting team gone to their training venue, Louth.
* Athletes team gone to their training venue, Boston.
Amr joined the Athletes in Boston.
The Egyptian Paralympics Atheletics Team going to their first training session in Boston. Dr Hamdy (Head Coach, middle), Eng. Mohamed Eassa (Coach, left) Captin Hosam (Assistant Coach, middle, 2nd row), Captin Mostafa (Athlete, left, 2nd row) and Dr Amr Ahmed (right) accompanying the team.
The Egyptian Paralympic Athletics team having lunch in Boston, following their first training session.
After the first training session, all teams returned back to the hotel, where the official welcome event was held, with the Deputy Mayor, Mayor of Boston, Councilour of East Lindsey, and the Egyptian and Arab communities.
Members of the Egyptian Paralympic Teams, Egyptian & Arab Community, and the Deputy Mayor, during the official welcome event of the pre-games training camp in Lincoln
Members of the Egyptian Paralympic Teams, Egyptian & Arab Community, and the Deputy Mayor, during the official welcome event of the pre-games training camp in Lincoln
Prof. Mohsen El-Mahdy, Chief De Mission, presented the Deputy Mayor with the Egyptian flag and decorated him with the Egyptian Paralympics Committee badge. Prof. Mohsen has also thank the Egyptian and Arab families and presented the Egyptian flagto Dr Amr Ahmed and decorated him with the Egyptian Paralympics Committee badge, as an appreciation for all the voluntary effort in preparation for this training camp.
Prof. Mohsen El-Mahdy (Chief De Mission) presenting the Egyptian flag to the Deputy Mayor of Lincoln, during the Official Welcome Event for the Egyptian Paralympic Teams at the beginning of their pre-games training camp in Lincolnshire.
Amr (Standing, right) with other guests including the Mayor of Boston (Sitting) and Mr Robin Wright (Left, the Manager of the University’s Sports Centre)Amr (right) holding the Olympic Torsh, with Roy Wright (left) the Olympic Torsh holder who came to welcome the Egyptian Paralympic Team in Lincoln and kindly brought the torsh with him. In the mean time, BBC Look North are recording in the back.
Then, the volly ball and table tennis teams had another training session at the sports centre.
Finally, the day is concluded by a Dinner with the Arabic community with traditional food.
The Egyptian Paralympics Teams arrived today, to start their pre-games training camp in Lincolnshire. Amr Ahmed welcomed the teams at Heathrow airport, with project managers from Lincolnshire Sports Partnership (Hayley Cook), Lincoln County Council (Sally Rate, Rachel Townsend), and a team of volunteers including Ghada Mohamed. The teams were transferred, buy 2 coaches, to Lincoln’s Holiday Inn Express where they are hosted for the training camp period.
Members of the Egyptian Paralympics Teams are getting on coaches, to leave Heathrow airport heading to Lincoln
It was an honour and a pleasure to welcome all memebers of the Egyptian Paralympics Teams and Officials, led by Prof. Mohsen El-Mahdy (Chief De Mission), and including Captin Yusri Awad and Dr Ahmed.
Later at night, a brief review of the schedule with the coaches, especially of the first day as it also coincides with Eid day (The Celebration after the Holy Month of Ramadan). Here (Left) is Captin Emad Ramadan for the Sitting Volly Ball team.
Amr had visited the Head quarter of the Egyptian Paralympics Committee in Cairo, 10 days ago, and had discussions with the Chief De Mission and officials for the final arrangements.