Text Analysis of User-Generated Contents for Health Related Applications
Deema Abdal Hafeth, Amr Ahmed, David Cobham
Text Analysis for Health Applications_Poster
Introduction
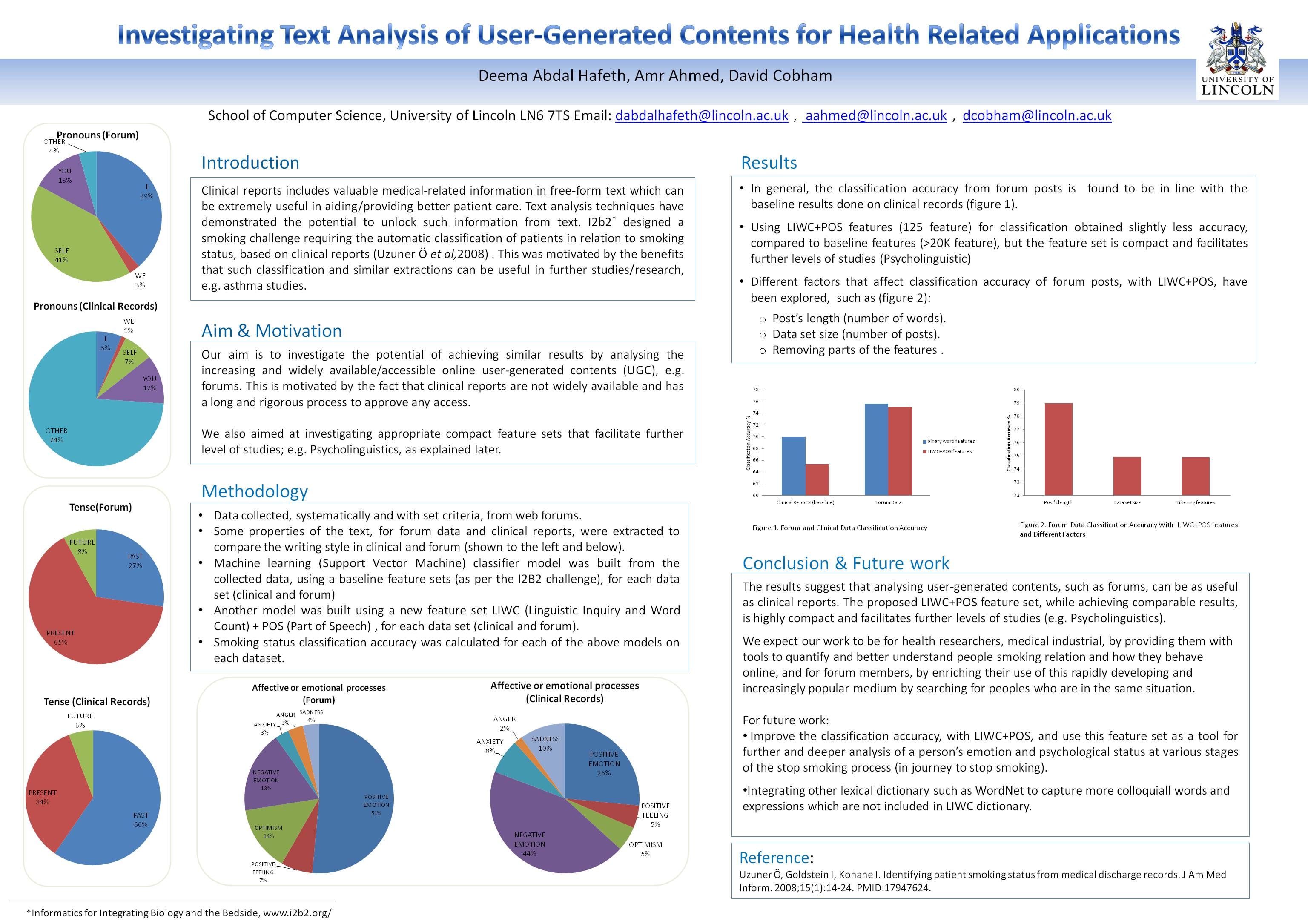
Clinical reports includes valuable medical-related information in free-form text which can be extremely useful in aiding/providing better patient care. Text analysis techniques have demonstrated the potential to unlock such information from text. I2b2* designed a smoking challenge requiring the automatic classification of patients in relation to smoking status, based on clinical reports (Uzuner Ö et al,2008) . This was motivated by the benefits that such classification and similar extractions can be useful in further studies/research, e.g. asthma studies.
Aim & Motivation
Our aim is to investigate the potential of achieving similar results by analysing the increasing and widely available/accessible online user-generated contents (UGC), e.g. forums. This is motivated by the fact that clinical reports are not widely available and has a long and rigorous process to approve any access.
We also aimed at investigating appropriate compact feature sets that facilitate further level of studies; e.g. Psycholinguistics, as explained later.
Methodology
Results
Conclusion & Future work
The results suggest that analysing user-generated contents, such as forums, can be as useful as clinical reports. The proposed LIWC+POS feature set, while achieving comparable results, is highly compact and facilitates further levels of studies (e.g. Psycholinguistics).
We expect our work to be for health researchers, medical industrial, by providing them with tools to quantify and better understand people smoking relation and how they behave online, and for forum members, by enriching their use of this rapidly developing and increasingly popular medium by searching for peoples who are in the same situation.
For future work:
Reference:
Uzuner Ö, Goldstein I, Kohane I. Identifying patient smoking status from medical discharge records. J Am Med Inform. 2008;15(1):14-24. PMID:17947624.